
0.はじめに
本企画は「世の中の身近な事象をデータサイエンスによって解明する」をコンセプトに、弊社のデータサイエンティストが実際に分析を行い、得られた示唆をみなさまにお届けします!
第一回では、東京都内で、もしマイホームを買うのであればどのエリアが最適であるかを、現在インターネット上で収集可能なデータを用いて、導き出していきました。
今回は、機械学習を用いて、筆者の興味のあるエリア(江東区)の物件価格の妥当性を機械学習によって検証していきます。
1.機会学習とは何か?
そもそも、機械学習とはどのようなものでしょうか?
機械学習とは、コンピューターシステムがデータから自動的に学び、予測や判断を行う方法です。機械学習では、大量のデータを基にパターンや関連性を見つけ、その法則に基づいた予測モデルを構築し、新しい数値を予測していきます。
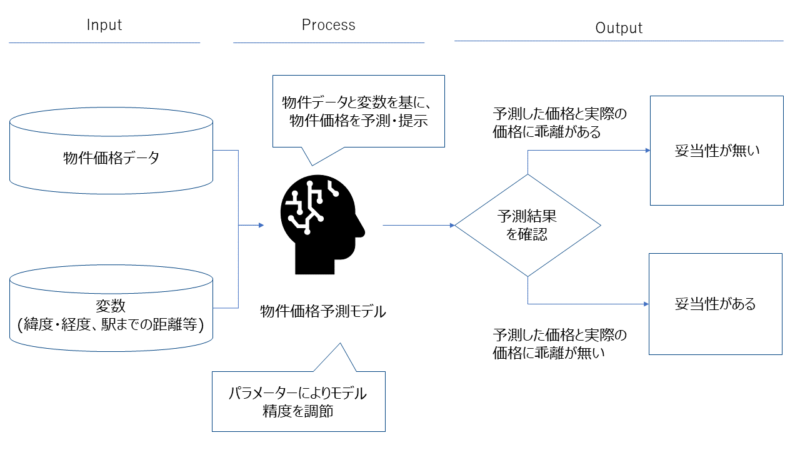
今回の場合、まずは物件価格と変数をインプットに回帰分析モデルを構築し、金額予測のパラメーターを導出してきます。
パラメーターとは、機械学習モデルがデータを理解するために調整する「設定」や「つまみ」のようなものです。
予測を行う上でどの変数が重要であるかをパラメーターにより、モデルの精度を調節していきます。
物件価格に影響を及ぼしそうな変数(駅からの距離、平米、築年数等)をモデルへ組み込み、モデルの精度を高めていきます。
では、モデルを用いてどのように物件価格の妥当性を判断するのでしょうか?
今回構築するモデルは、様々な条件(変数)を加味した本来あるべき物件価格を予測します。
予測した物件価格と実際の価格を見比べ、そのギャップが少ない程、妥当性のある価格と判断することができます。
2.機械学習の手順は?
どのように機械学習を進めていくのでしょうか?
本項では、機械学習のプロセスとプロセス毎の詳細を、物件価格の予測モデルの構築を実例に紹介します。
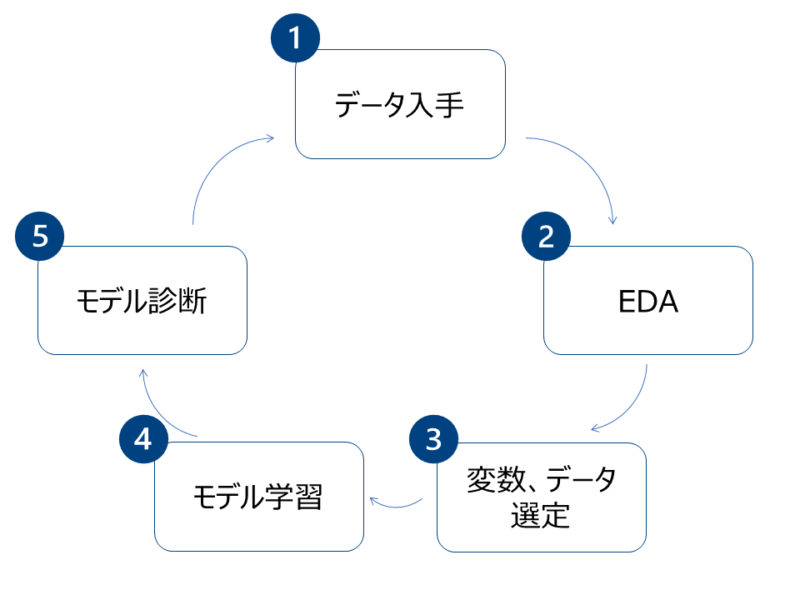
モデル構築の全体の流れは、①データ入手②EDA(探索的分析)③変数、データ選定④モデル学習⑤モデル診断です。
データの入手後、EDA(探索的分析)を通じてデータ間での相関関係を確認し、必要なデータを使ってモデルを構築していきます。
基本的に一回のサイクルでモデルが完成するケースは少ないため、②∼⑤のサイクルを素早く回していくことが重要です。
それでは実際に、①~⑤のサイクルを、物件価格の分析をしながら各プロセスをみていきましょう。
①データ入手
まずは、分析・モデル構築に必要なデータを収集していきます。今回は、江東区内2LDK、2DKの物件情報(800件程)を収集しました。
データ収集時のポイントは、機械学習を行えるだけのデータ品質が保たれているか留意することです。
もし、大量にデータが入手できたとしても、品質が低ければ(正確でない、データ形式が分析に向いていない等)使うことができません。データが正確で信頼性のあるものであるか確認し、不正確なデータやノイズを取り除くことが重要です。
②EDA(探索的分析)
収集したデータを使って、分析をしましょう。分析観点は、「緯度・経度毎の物件価格の相関性」です。
まずはGoogle Geocodeを使って、物件毎の緯度・経度の情報を収集し、物件価格を確認します。

上の図は、江東区エリアの物件価格をマップ上に配置したもので、色が濃い程価格が高いです。
図を見てみると、有明、豊洲、隅田川沿いのエリアは価格が高く、内陸側は比較的低いことが分かります。そのため、緯度・経度と物件価格には相関関係があるかもしれないということが分かりました。
③変数、データ選定
EDAで得られた示唆を基に、以下のデータ(変数)を用いて、物件価格予測モデルを構築します。
・緯度・経度、駅から距離、物件面積、バルコニー面積、築年数
※モデルの中身(コード)は複雑なので、今回の記事での説明は省略させていただきます。
④モデル学習・診断
モデルを作った後は、モデル診断を行うことで、精度が十分であるかを確認していきます。
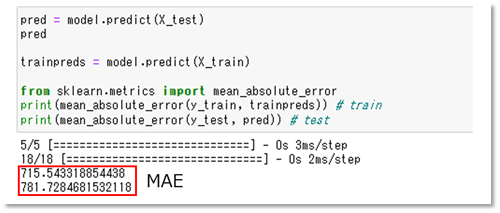
上の図は、モデル診断結果を表したものになります。
診断の際に、見るべき指標の1つとして、「MAE(Mean Absolute Error)」が挙げられます。
MAEとは、予測した値と実際の値との差(誤差)の絶対値の平均を表す指標で、MAEが小さいほど、モデルの予測が実際の値に近いことを意味します。
診断の結果、このモデルの場合、予測と実際の値の誤差が700万円を超えてしまっており、誤差が大きいため、物件価格の予測に活用することができません。
⑤EDA(2回目)
では、モデルの精度が低かった要因は何だったのでしょうか?

まずは、分析の切り口が正しかったのかを確認してみます。
右上の図は緯度・経度と物件価格を精緻にグラフ化したものです。左上の図(EDA1回目の分布図)と比較すると、2回目の分布図の方が複雑であり、必ずしも緯度・経度と物件価格には相関関係があるとは断定できないことが分かります。
モデルの改善へ向けて、エリア区分を精緻化するため郵便番号を切り口とした分析を行います。
⑦モデル学習・診断(2回目)
郵便番号を4つのグループに分類し、再度機械学習を行いました。
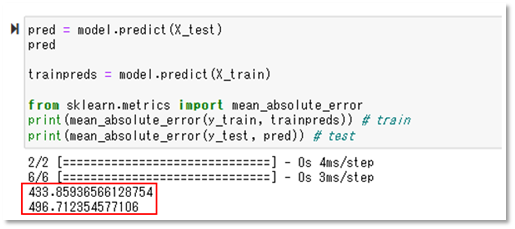
上の図は、2回目のモデル診断結果を表したものとなります。
モデルを診断した結果、MAEが500万円を切っているため、前回に比べて誤差が小さくなっていることが分かります。
どうやら、郵便番号と物件価格には相関関係がありそうです。
ここから更に、モデルの精度を高めていきます。
精度を高めていくには、他の変数を使用しなければなりません。
現在、活用できそうなデータは商店街、病院、学校等のインフラ施設と物件間の距離です。
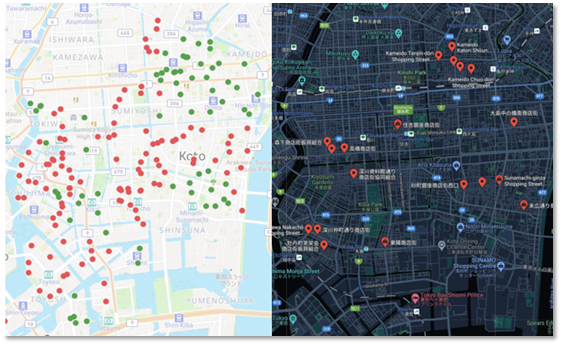
左上の図は、モデルが予測した値と実際の値の誤差の大きさをエリア別に分布させたもので、赤色は誤差が大きいことを表しています。
右上の図は、同エリアの商店街をマークアップしたものです。
左上の図を見ると、亀戸、南砂町、木場周辺ではモデル精度が担保されており、それ以外のエリアは精度が低いことが確認できます。
このモデル精度のマッピング図と商店街をマークアップした図を見比べると、商店街エリアがある地域は、予測の精度が担保されやすいということが分かります。
よって、モデルの精度を高めていくには、商業施設や学校などのインフラ施設と物件間の距離データの活用が有効であるという仮説が設定できるため、モデルへ追加学習させていきます。
ここまでが機械学習の流れとなります。
3.モデルによる予測結果
実際に、インフラ施設と物件間の距離データを追加したモデルを用いて予測をしていきましょう。

上の図は、ある江東区内の物件情報(価格:3480万円)になります。こちらの情報をモデルにインプットさせ、物件価格を予測してもらいます。

上の図が、江東区内の物件情報をインプットに、モデルが予測した結果になります。
モデルが予測した価格は約3737万円でした。
MAEは400万円以内と最小限の誤差であり、入力した物件価格の妥当性はあると判断することができます。
4.終わりに
以上が今回のレポートでした。いかかでしたか?
皆様が本レポートを通じて、機械学習の仕組みとプロセスについて知っていただけたら幸いです。
身近なテーマでもデータサイエンスの活用余地があるということが分かりました。
最後になりますが、ご一読いただきありがとうございました。
今後ともよろしくお願い申し上げます。
この記事についてのお問い合わせはこちら⇒問い合わせフォーム
※「お問い合わせ内容」の覧に、記事名もしくは記事URLをご記載ください
採用情報はこちら⇒Pactera Recruit
現場コンサルタントとの面談等も対応可能ですので是非お気軽にお問い合わせください!
※免責事項
この分析はあくまでも機械学習の仕組みと方法論に関する紹介が目的であり、投資の判断材料ではございません。投資に関する決定はご自身の判断で行うようお願いいたします。

